 macklus
macklusVivimos en una época en la que Internet domina las comunicaciones y casi las relaciones entre personas, y si tenemos un pequeño...
Analizar uso de S3 con CloudTrail y Athena
 macklus
macklus You can also read this entry in english by clicking here.
Hace unos días, al analizar el consumo de S3 de uno de nuestros proyectos de cabecera, vimos que el coste estaba disparado. En este proyecto usamos S3 como almacén de imágenes estáticas, al que se accede desde una distribución de CloudFront, por lo que no debería ser muy elevado.
Uno de los problemas de utilizar este tipo de configuraciones es que, ante un problema como este, procesar y depurar los posibles fallos de concepto o funcionamiento es muy complicado, ya que tanto CloudFront como S3 son servicios gestionados por AWS, y nosotros no tenemos un acceso directo a la información de depuración. Para poder hacer este análisis debemos utilizar los servicios de AWS CloudTrail, S3 y Athena
El proceso de análisis
El proceso que se va a seguir para llevar a cabo el análisis se muestra en la imagen siguiente
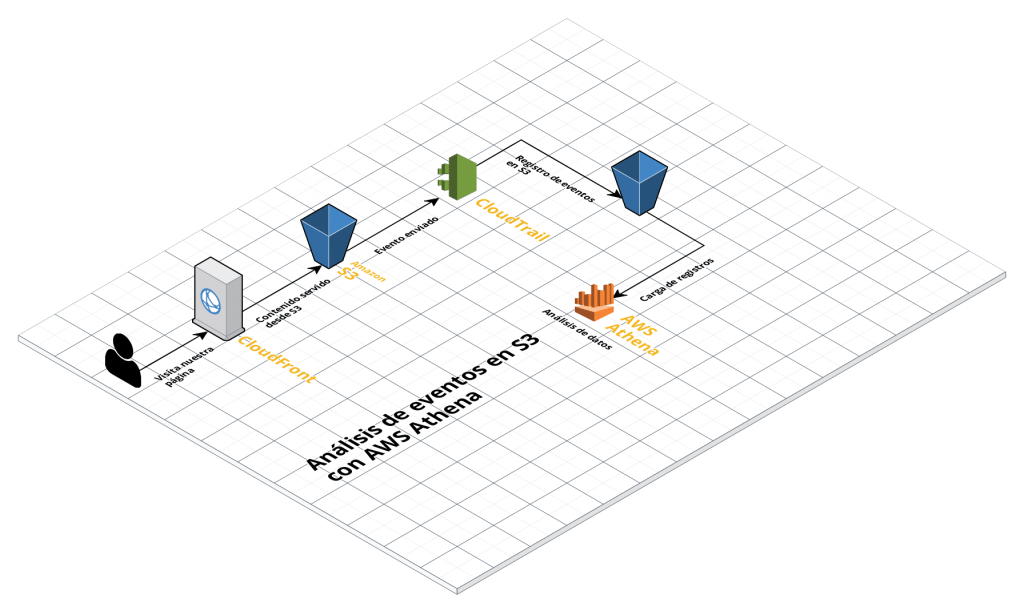
Los pasos para configurarlo van a ser:
- Configurar CloudTrail para que guarde los eventos de S3 en un bucket de S3
- Configurar Athena para que lea los datos de S3
- Analizar los registros con Athena
Configurar CloudTrail para guardar los eventos de S3
AWS CloudTrail es un servicio para la auditoría en los servicios web de Amazón. Para cada una de las auditorías que queramos realizar, debemos crear un «trail» que guardará la información en S3, bien para su almacenaje o bien para su análisis posterior.
Para crear un nuevo trail, iremos a la consola de CloudTrail, y:
- Pulsamos en el botón «Create Trail»
- Indicamos el nombre en la casilla «Trail name»
- Seleccionamos «no» en la casilla «Apply trail to all regions»
- Seleccionamos «None» en la casilla «Read/Write events»
- En la pestaña «Data events» debemos indicar el bucket o buckets de S3 que queremos auditar
- En la pestaña «Storage location» debemos indicar el bucket S3 donde queremos guardar los registros (lo recomendado es crear un bucket nuevo)
Ahora, debemos esperar un tiempo hasta que los registros empiecen a aparecer en nuestro bucket S3.
Configurar Athena para que lea los datos de S3
Para que AWS Athena sea capaz de interpretar los datos de registro que hemos guardado en S3, es necesario crear una tabla de Athena, e indicarle la estructura de los archivos de registro. Así, Athena puede separar y analizar los datos de cada entrada de registro, y nos permitirá hacer querys complejas sobre ese contenido.
Para crear la nueva tabla y definir los registros, podemos usar el propio lenguaje de Athena, lanzando la siguiente query desde el editor:
CREATE EXTERNAL TABLE cloudtrail_logs (
eventversion STRING,
useridentity STRUCT<
type:STRING,
principalid:STRING,
arn:STRING,
accountid:STRING,
invokedby:STRING,
accesskeyid:STRING,
userName:STRING,
sessioncontext:STRUCT<
attributes:STRUCT<
mfaauthenticated:STRING,
creationdate:STRING>,
sessionissuer:STRUCT<
type:STRING,
principalId:STRING,
arn:STRING,
accountId:STRING,
userName:STRING>>>,
eventtime STRING,
eventsource STRING,
eventname STRING,
awsregion STRING,
sourceipaddress STRING,
useragent STRING,
errorcode STRING,
errormessage STRING,
requestparameters STRING,
responseelements STRING,
additionaleventdata STRING,
requestid STRING,
eventid STRING,
resources ARRAY<STRUCT<
ARN:STRING,
accountId:STRING,
type:STRING>>,
eventtype STRING,
apiversion STRING,
readonly STRING,
recipientaccountid STRING,
serviceeventdetails STRING,
sharedeventid STRING,
vpcendpointid STRING
)
ROW FORMAT SERDE 'com.amazon.emr.hive.serde.CloudTrailSerde'
STORED AS INPUTFORMAT 'com.amazon.emr.cloudtrail.CloudTrailInputFormat'
OUTPUTFORMAT 'org.apache.hadoop.hive.ql.io.HiveIgnoreKeyTextOutputFormat'
LOCATION 's3://s3-inspect-bucket/AWSLogs/';Con ésta query crearemos la tabla cloudtrail_logs, que luego usaremos para hacer las distintas peticiones. Es importante tener en cuenta que el campo de LOCATION debe apuntar al bucket S3 donde estemos guardando los registros.
Es importante tener en cuenta que Athena nos va a cobrar por cada petición, según el volumen de datos que analicemos, así que es recomendable usar un grupo de datos pequeño para depurar las querys, antes de ejecutarlas contra el grupo de datos total, para evitar que el coste se pueda disparar.
Analizar los registros con Athena
Para analizar los registros con Athena, iremos creando querys en lenguaje SQL muy similar al estandar.
En mi caso, que queríamos depurar el uso que se estaba haciendo de S3, estas son las querys que utilicé:
Ver el número de peticiones a cada bucket S3
SELECT
COUNT(*) as total,
CAST(json_parse(requestparameters) AS MAP(VARCHAR, VARCHAR))['bucketName'] AS bucketName
FROM cloudtrail_logs
GROUP BY
CAST(json_parse(requestparameters) AS MAP(VARCHAR, VARCHAR))['bucketName']
ORDER BY total DESC;En este caso, como el nombre del bucket está dentro del campo requestparameters, debemos sacarlo del objeto JSON que lo forma.
Agrupar las peticiones por UserAgent
SELECT
COUNT(useragent) as total,
useragent
FROM cloudtrail_logs
WHERE CAST(json_parse(requestparameters) AS MAP(VARCHAR, VARCHAR))['bucketName'] = 'testbucket-data'
GROUP BY
useragent,
CAST(json_parse(requestparameters) AS MAP(VARCHAR, VARCHAR))['bucketName']
ORDER BY total DESC;Una vez que ya sabíamos el bucket donde se realizaban la mayor parte de las peticiones, con ésta query sacamos el UserAgent de los clientes que están realizando las peticiones.
En este caso hemos usado el UserAgent de la petición para ver quien nos estaba haciendo las peticiones, ya que los procesos internos de AWS también nos envían un UserAgent y nos permiten discriminar el origen.
Mostrar las keys de S3 más solicitadas
SELECT
COUNT(CAST(json_parse(requestparameters) AS MAP(VARCHAR, VARCHAR))['key']) as total,
CAST(json_parse(requestparameters) AS MAP(VARCHAR, VARCHAR))['key'] AS key
FROM cloudtrail_logs
GROUP BY
CAST(json_parse(requestparameters) AS MAP(VARCHAR, VARCHAR))['key']
ORDER BY total DESC
LIMIT 100Con ésta petición mostramos las 100 keys de S3 que más peticiones han recibido, mostrando también el número de peticiones total. Ésta query nos sirvió para ver que había varias keys que estaban recibiendo un número anormalmente alto de peticiones, y depurar cual era el problema.
